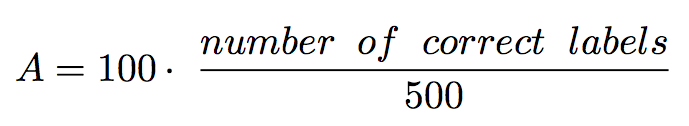Overview
The CVC-MUSCIMA database will be used for the competition. This database consists of 1,000 handwritten music score images, written by 50 different musicians. All the 50 writers are adult musicians in order to ensure that they have their own characteristic handwriting music style. Each writer has transcribed exactly the same 20 music pages, using the same pen and the same kind of music paper.For the competition, we will provide images without the staff lines. The staffless images are particularly useful for writer identification: since most writer identification methods remove the staff lines in the preprocessing stage, this eases the publication of results which are not dependant on the performance of the particular staff removal technique applied. Moreover, these images make easy the participation of researchers that do not work on staff removal.
For the competition the dataset is equally divided into two parts, of which the 50% of the images (500 images, 10 images from each of the writers) will be used for training the algorithms and the other 50% of the images will be used for testing them.
Input files
The following training data is available for download (click here):
Test Files
The
test set is comprised of 500 unlabeled binary staffless images.
The naming convention is test-XXX.png, where XXX ranges from 001
to 500.
The test set and its ground-truth are now
available here.
The participants will be asked to send the following two files
by email to afornes@cvc.uab.es:
Metrics
A musical score will be considered as correctly
classified if the writer (in this case writer number) decided by
the algorithm is the same as the ground truthed one. The
evaluation metric will be the classification accuracy, that is: