The CVC-MUSCIMA database contains handwritten music score images, which has been specially designed for writer identification and staff removal tasks.
The database contains 1,000 music sheets written by 50 different musicians. All al them are adult musicians, in order to ensure that they have their own characteristic handwriting style. Each writer has transcribed the same 20 music pages, using the same pen and the same kind of music paper (with printed staff lines). The set of the 20 selected music sheets contains music scores for solo instruments and music scores for choir and orchestra.Characteristics
The original 1,000 music scores have been scanned at 300 dpi
and 24 bpp. Later, they have been converted to 8 bit gray
scale.
The staff lines were initially removed using color cues, and
manually checked for correcting errors.
Finally, the music scores have been distorted for staff
removal purposes and converted to binary images.
Two different ground-truthed images have been created,
depending whether the aim is writer identification or staff
removal.

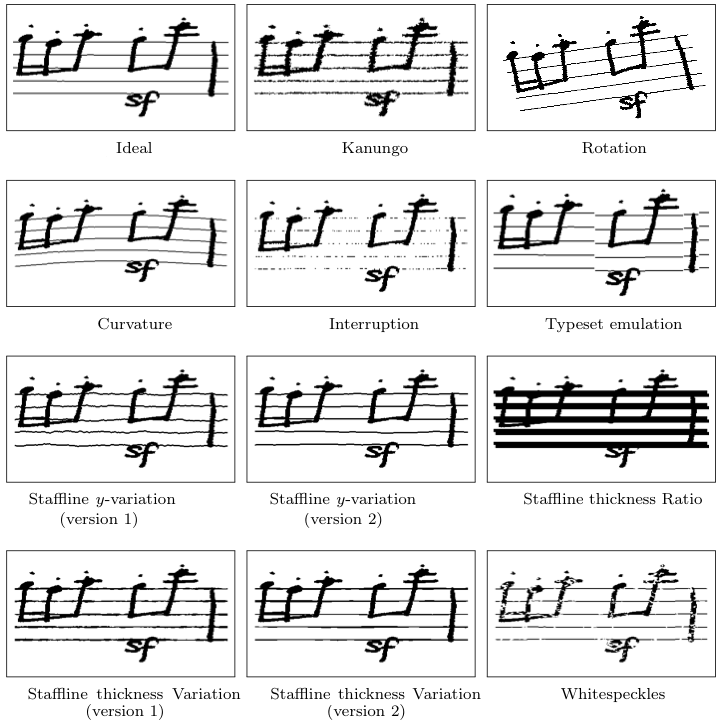
| Degradation with Kanungo noise | Rotation | Curvature |
| Staffline interruption | Typeset emulation | Staffline y-variation |
| Staffline thickness ratio | Staffline thickness variation | White speckles |
[1] Alicia Fornés, Anjan Dutta, Albert Gordo, Josep Lladós.
CVC-MUSCIMA: A Ground-truth of Handwritten Music Score Images for
Writer Identification and Staff Removal. International Journal on
Document Analysis and Recognition, Volume 15, Issue 3, pp 243-251,
2012. (DOI: 10.1007/s10032-011-0168-2).
[2] Christoph Dalitz, Michael Droettboom, Bastian Pranzas and
Ichiro Fujinaga. A Comparative Study of Staff Removal Algorithms.
IEEE Transactions on Pattern Analysis and Machine Intelligence
30(5), pp.753-766. 2008. (DOI: 10.1109/TPAMI.2007.70749) (the authors have
a free archived version here).
If you have any questions or suggestions, please contact
Alicia Fornes: afornes@cvc.uab.es.

{kind=link}